
Apache Cassandra.
Apache Beam, Spark.
Airflow, AWS: S3, Redshift.
Fundamental concepts + terminology in Machine Learning.
Scalability + Frameworks.
Interview Prep Strategies.
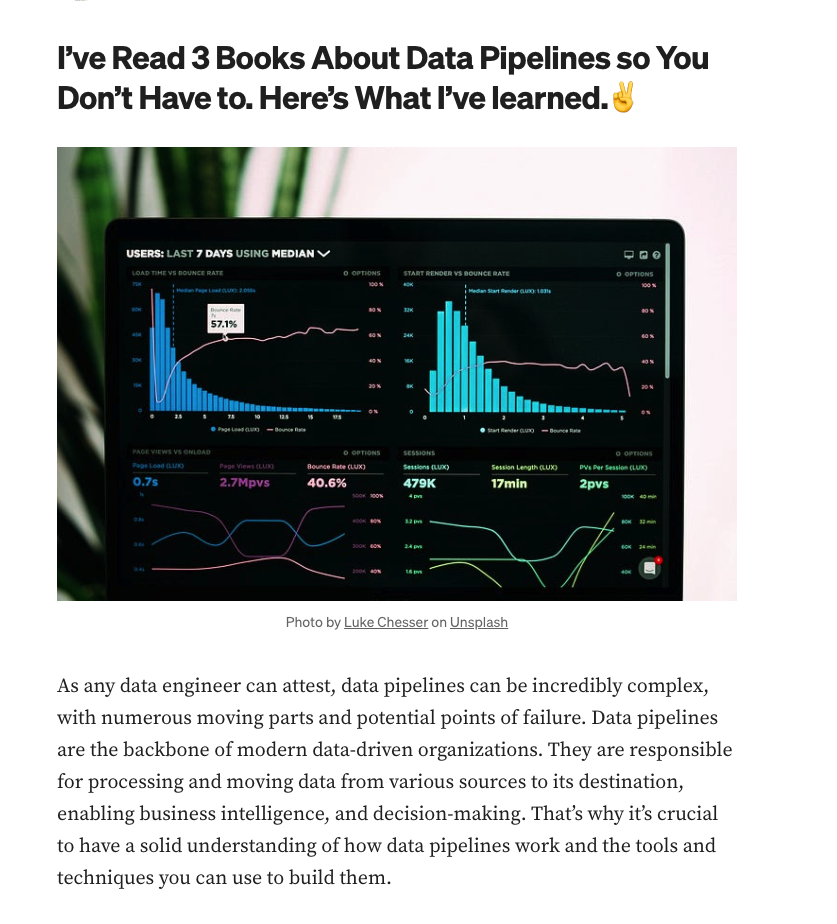
Data engineering is a rapidly growing field that plays a crucial role in enabling data-driven decision-making for businesses. Data engineers design and build the infrastructure necessary for processing, storing, and analyzing large amounts of data. In this informational blog, my goal is to discover what it takes to become a really good data engineer.
1. Fundamentals. Data Engineers need to have strong programming skills. Ideally, one should get proficient in languages like Python, Java, or Scala, and be able to manipulate data efficiently. Additionally, upcoming data engineers should build projects that provide them experience with data processing frameworks like Apache Spark or Apache Flink.
2. Knowledge of data modeling and data warehousing. Data Engineers expertly leverage concepts like SQL, ETL (Extract, Transform, Load), and data modeling. Moreover, data engineers should also be experienced with technologies like Hadoop, Hive, or Redshift.
3. System Design + Distributed systems. Data engineers utilize computing concepts like MapReduce, sharding, and replication. This knowledge enables them to design and implement efficient and scalable data pipelines that can handle large volumes of data.
TDLR:
Becoming a good data engineer requires a combination of technical skills, problem-solving abilities, and effective communication. By mastering programming languages, understanding databases and data warehousing, and possessing knowledge of distributed systems, data engineers can create efficient and scalable data pipelines. Moreover, by continuously learning and adapting to new technologies, data engineers can stay ahead of the curve in this rapidly growing field.